LLM信息空间的映射
乘法
- 两个32bit的浮点数乘法,相当于32位的bit向量做空间映射
- 每个bit代表了特殊的含义,指数、尾数以及对应的档位
- 乘法不能充分利用32位的所有表达空间,精度越低的数据信息利用率越高
多层映射(等高线)

线性映射 非线性映射

非线性Dot
-
对B进行非线性映射,A = B *(C+D) 等价于 A = B*C + B*D ,ABCD都是矩阵
- 实际上增加了映射的空间灵活度,实验下来,使用得当可能可以提升精度
-
ResNet的典型 A = B*C + B
- 显然D是1,不对B进行改变
LLM的映射行为
- 每一层都根据前面的数据映射到另外一个表示空间
- 多层的LLM可以等价于一个大型卡罗搜索树
- 剪枝的,均匀宽度的
- 大规模参数,多维度
- 行为可以比喻为Plinko(中文常译为“钉板游戏”或“弹珠盘”)
- 从上到下不断在转换在对应空间内的分类
- 当前layer的所有token的所有hidden status的所有可能数值共同表示了所有的可能分类
- 最终的hidden status都对应了一个token
- 宏观来说
- 每个token的单体空间(不大)组合成的组合空间(很大)就是一句话
- LLM进行编码(编码可以没有)+ 解码 生成(映射)另外一个组合空间,也就是输出的一句话
- 因为组合空间非常大,需要按照空间的规律进行有限的映射

信息的表示
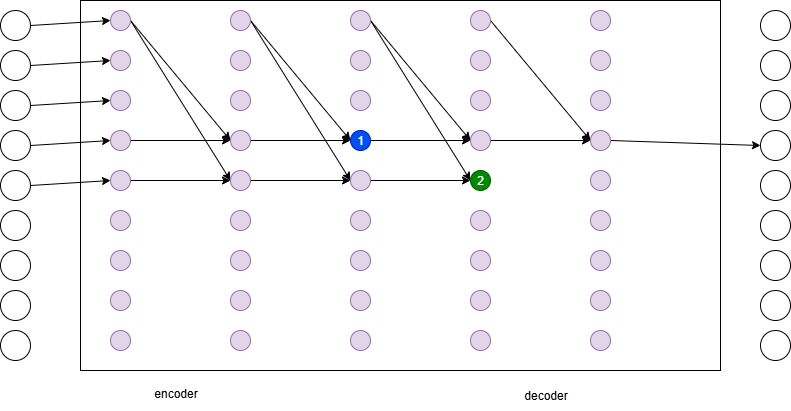
- 所有内部节点表示:同层的所有前面token的总结(映射)的结果
- 矛盾:既要表达当前节点的局部语义,又要表达到当前token的整体语义
No comments to display
No comments to display