神经网络的逻辑
量化
量化不是没有代价。Llama3模型的量化效果比Llama2模型要差,量化过程中的质量损失更大。
直觉是,一个训练不足的模型受到量化的影响较小,因为其训练过程并没有充分利用每一个权重。关于Llama的一个关键发现,以及它为何能在其大小范围内表现出色,是因为它们在比文献中所谓的“最佳”状态更大的数据集上训练了更长时间。
综合这些因素,似乎可以得出以下结论:小型模型、大量数据、长时间训练>大型模型+量化。基本上,量化是一种用于缩短长时间训练的损失性的捷径。数据的数量和质量,一如既往是所有这些中最重要。
首先,研究人员发现大语言模型的Hessian矩阵表现出极端的长尾分布特性。这也意味着大多数位置权重的变化对模型的输入输出并不敏感,而少部分元素对于权重的输出非常敏感。其次,大语言模型中的权重密度遵循不均匀的钟形分布形式。
用 数据精度限制的特性直接替代Softmax
Batch Normalization
BN使得结果(输出信号各个维度)的均值为0,方差为1。为了防止“梯度弥散”
- 可以使用更大的学习率,训练过程更加稳定,极大提高了训练速度。
- 可以将bias置为0,因为Batch Normalization的Standardization过程会移除直流分量,所以不再需要bias。
- 对权重初始化不再敏感,通常权重采样自0均值某方差的高斯分布,以往对高斯分布的方差设置十分重要,有了Batch Normalization后,对与同一个输出节点相连的权重进行放缩,其标准差𝜎也会放缩同样的倍数,相除抵消。
- 对权重的尺度不再敏感,理由同上,尺度统一由𝛾参数控制,在训练中决定。
- 深层网络可以使用sigmoid和tanh了,理由同上,BN抑制了梯度消失。
- Batch Normalization具有某种正则作用,不需要太依赖dropout,减少过拟合。
激活函数
非线性激活函数对于神经网络容量至关重要,没有它们,神经网络只是大型因式分解线性模型。研究结果表明,ReLU显著增强了模型的容量。虽然它最初的作用是为了减轻梯度的消失和爆炸,但ReLU还提高了网络的数据拟合能力。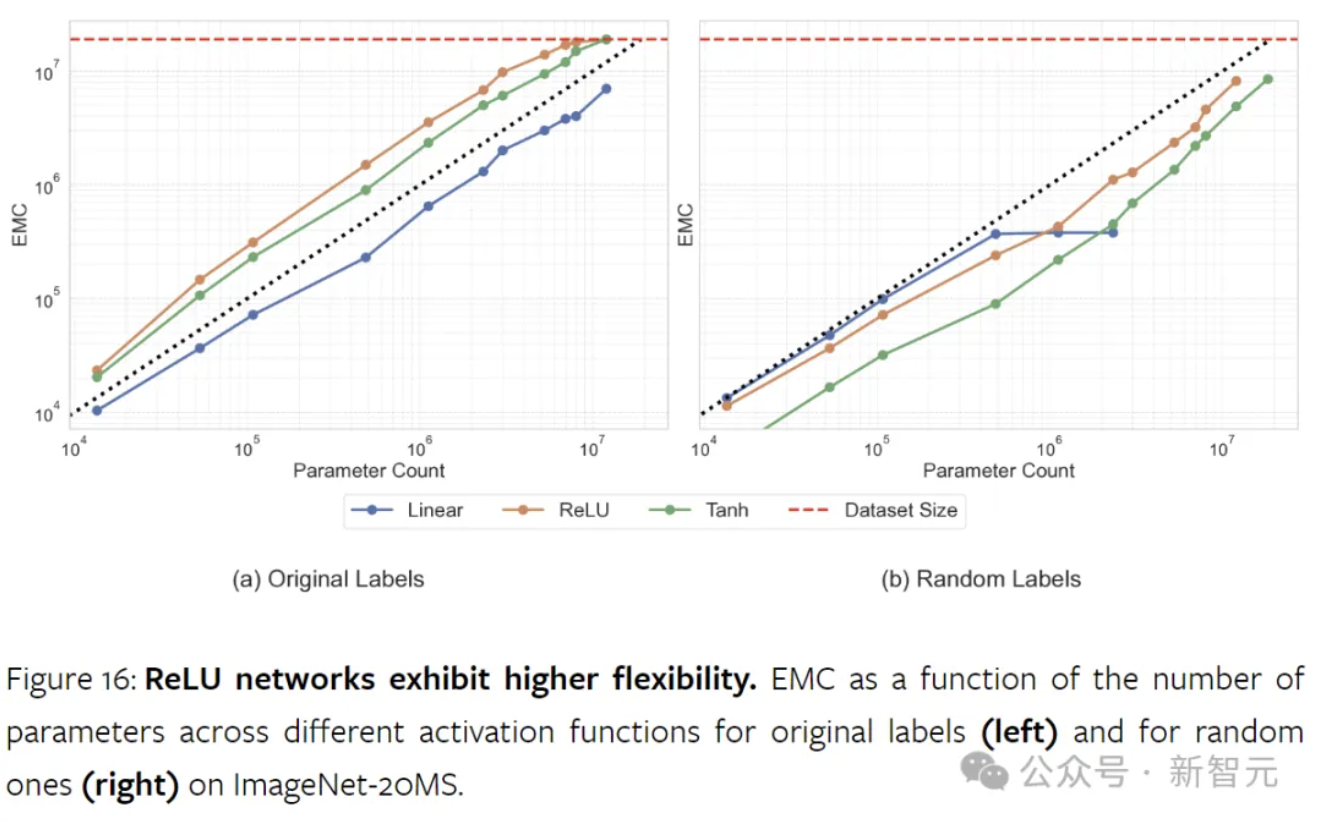
- Sigmoid
- 软饱和性,容易产生梯度消失,导致训练出现问题
- 是不是不同层使用不用的激活函数?越初层,信息绝对性越差,不能使用sigmoid
- 输出不是以0为中心
- 软饱和性,容易产生梯度消失,导致训练出现问题


- tanh
- 和sigmoid一样存在梯度消失的问题


- RELU
- 收敛得更快
- 计算简单,计算快
- 会造成神经元死亡,比如输出总是0,不可逆得死亡了
- 可能是因为在0附近得不连续
No Comments