GMP
- 目标
- 软硬件结合
- 大量依靠软件优化,发挥最大的物理效率,同工艺下架构效率达2倍
- 算法和硬件协同优化,同模型精度条件下效率达4倍
- DRAM或者多机的不确定数据延迟直接整合到算法处理,硬件不做竞争
- 硬件采用固定的LUT计算(可能不能等价到矩阵乘法,甚至是乘法本身)
- 全模型网络级别优化,利用编译器对整个模型进行搜索优化,生成静态计算图
- 软硬件结合
- 架构考虑
- 动态性的表达
- 硬件竞争的管理
- 灵活性,扩展性,从edga到集群
- 自举,所有单元支持自配置,自启动
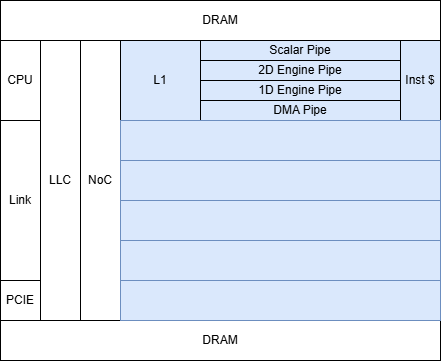
- 架构方案
- 图:编译整个动态计算图,支持 Fork(launch) join sync
- 平铺:按照可编程硬件单元进行编程,为每个单元生成一定数量的逻辑线程, 支持 sync
- ... ...
- 规格
- 指令流
- load和fetch
- 基于图的信息,和数据流一样得方式,需要发命令和同步
- ISA
- Launch
- Sync