Skip to main content
GMP
- 背景
- 适应未来的AI计算需求
- 存储足够量的权重,但是明显的热点内容访问
- 强动态性,大范围、
大量的随机动态访问多次的随机动态访问
- 节能、低带宽需求
- 低延迟
- 目标
- 软硬件结合
- 大量依靠软件优化,发挥最大的物理效率,同工艺下架构效率达2倍
- 算法和硬件协同优化,同模型精度条件下效率达4倍
- DRAM或者多机的不确定数据延迟直接整合到算法处理,硬件不做竞争
- 硬件采用固定的LUT计算(可能不能等价到矩阵乘法,甚至是乘法本身)
- 全模型网络级别优化,利用编译器对整个模型进行搜索优化,生成静态计算图
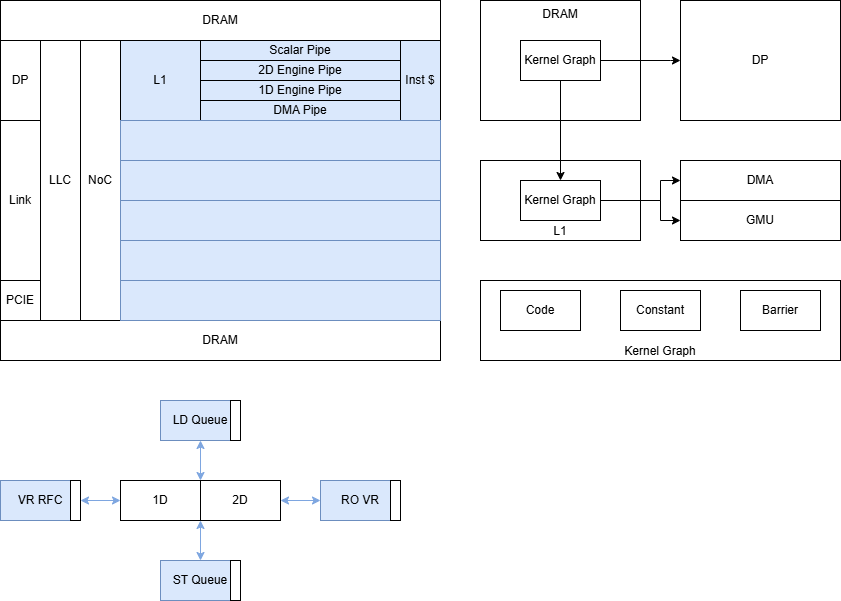
- 指令控制流水线
- 指令明确指定指令的调度、L0 Cache的使用、依赖关系的建立和解除
- 统一的异步通讯管理方案
- 整个系统有大量的不同的通讯和同步机制
- 流水线内的credit,L1的数据缓冲
- 算力核之间的数据交互核同步,NoC的各种协议
- L2/L3的复用
- 分布式栈:网卡的片上调度,网络的延迟不确定性,通路的复用
- outstanding/各种缓存的管理和设计
- 异步的调度
- launch控制及指令加载加速
- 统一的数据流拆分模型
- 提供统一的编程模型对数据流进行描述
- 硬件加速的数据流动态计算,减少冗余且高成本的除法/模运算的地址计算
- 通过自动的预计算和特殊硬件加速
- 自动处理的原子操作,以消除写入全局内存时的warp级串行化
- 自动进行乒乓双缓冲机制
- 架构考虑
- 动态性的表达
- 硬件竞争的管理
- 灵活性,扩展性,从edga到集群
- 自举,所有单元支持自配置,自启动
- 线程内的依赖都是静态的软件调度,软件直接调度流水线,减少硬件的调度
- 架构方案
- 图:编译整个动态计算图,支持 Fork(launch) join sync
- 平铺:按照可编程硬件单元进行编程,为每个单元生成一定数量的逻辑线程, 支持 sync
- ... ...
- 规格
- 指令流
- load和fetch
- 基于图的信息,和数据流一样得方式,需要发命令和同步
- ISA
- Launch
- Sync