Dynamic Graph Multi Processor 架构
背景
- Etched提出,GPU在过去四年间效率并没有变得更好,只是变得更大了:芯片每平方毫米的的TFLOPS几乎持平。
- 「干净数据+大模型」和「脏数据+大模型」的效果,不会有太大差异。
- Etched团队表示,H100有800亿个晶体管,却只有3.3%用于矩阵乘法,这种大模型推理时最常见的运算。只支持Tranformer的Sohu芯片FLOPS有效利用率超过90%(GPU大约是30%)
- 在前Scaling Law时代,我们强调的是Scale Up,即在数据压缩后争取模型智能的上限;在后Scaling Law时代,需要比拼的则是Scale Down,即谁能训出更具「性价比」的模型。
核心特点
- 针对AI应用,极高的规格参数
- 抛弃传统计算机的特性,只支持Int8,加减乘,固定的数据流水pattern,固定的计算管线
- 算子的输出输入精度更低,计算精度更高,自动混合精度
- 脉冲阵列,多周期指令(超级大的2D指令)=> 提高算力密度??
- GPU的核心问题就是:管理DRAM的延迟和有限的带宽
- 所有的硬件单元(包括NoC,Cache等)都在执行一张计算图,通过统一的图关系指令(Fork/Join)来运行,软件可以精细得控制所有的硬件单元,甚至是NoC得flow control行为。
- 软件控制内存一致性问题,传递信息到NoC/Cache,硬件不做自动化处理
- 传统上架构,内存一致性(consistency corhenrency) 需要通过fence+sync功能来保证,非常麻烦和易错。
- GMP通过显式的同步模型(fork/join)来管理同步关系
- 线程内的利用静态的依赖关系来尽量避免fence的使用
- 线程间的编译器自动掺入fence指令
- 全异步,各种单元之间可以主动同步,每种单元(IP)都可以执行一些指令,都是一个cpu核,执行自己的代码和调度,区别于传统设计,从IP一般都是通过主IP进行控制,比如cache单元被处理核通过cache_hint进行配置
- 边缘端的越级大模型,极度定制的芯片
- 固定的计算单元的组合(DSA)
- 整个SOC级别的动态调度
- 以NOC为编程中心的调度和数据流
- 标量单元,向量单元,张量单元灵活组合,操作数(寄存器)可以灵活转换
- 充分把合理的计算放到合理的单元,节省面积和功耗:一个标量x一个张量
- 充分利用软件的编译
- DSA的效率,GPU的灵活性
计算抽象
- 信息维度映射,信息过滤,信息选择 :Dot / GEMM => Join+Reduce
- 激活 : ElementWise Broadcast
- 统计、动态选择、排序 : Reduce 、G/S
- 随机数生成
- 是不是可以把所有的计算都抽象成查找表的方式
- 操作的方式由操作码+密码数来指定,实际上是定义一个查找表
- 操作码可以是指令的imm,密码数可以是约定的,也可能是提前载入的
- 乘法等价?
-

动态/静态
- 动态和静态的范围
- 全静态(graph)调度逻辑,包括DRAM都静态调
- 通过LLC隔离DRAM的动态性,LLC以下全静态 L3->LLC->DMA->L1->L0->MALU
- 静态图
- 利用fork/join(硬件加速)描述所有的并行性,比如 L1/L0的服用,DMA的操作后同步
- 有并行就有调度器,有调度就有缺陷
- 动态
- Root 调度 & 核内调度 & 流水线调度
- 数据流、NoC、Cache
- Fork Join
- 充分利用CPU领域的灵活性,RISCV多核,加速的硬件调度指令(地址计算,IP配置等),同步指令,ForkJoin等
- 静态
- NPU流水线,NPU Kernel,1D 2D指令及组合
- DSA Confige
- Atomic Reduce专用加速硬件,近存储计算,压缩解压缩
- LD/ST+Relu专用硬件
特点
- NPU的流水线延迟固定,包括LD/ST(编译器已知),都是从L2/L1 <-> L2/L1
- 都是MLI指令,可以打包成HLI指令,不支持跳转等
- 不支持不对齐? 不对齐是不是延迟就未知了
- 同时只能执行一个任务(一堆MLI指令)
- 指令堆会有 Leading/Tainling 时间,scheduler感知得到,可以进行调度,前后两条可以自动pipeline,NPU本身不考虑依赖
- 强大的软件仿真和验证平台,减少硬件的debug需求,大大简化硬件的调试/检查/报错功能
和GCU区别
- MLI不是硬件拆分?由编译器拆分,为了减少硬件的难度
- scheduler控制NPU的指令搬运、
- 明确latency
- 支持打包成HLI
方案
- 多GM之间共享数据及同步
- scheduler可以做及其动态的交互和同步
- 内存墙
- 自动精度缩放,权重存储的是<8bit,DMA搬运的时候变成8bit,每个参数都可以进行不同bit的缩放
- Launch/Sync/DataFlow
- 高效的实现Launch和Sync,抽象出Fork/Join指令
- 主动Fork和Join的不一定是同一个对象,可以A fork B,C join B
- fork等价与launch,join等价与wait
- 可以一次性fork多个,也可以一次性join多个
- 硬件单元存储一个fork出来的任务的队列进行调度执行,不同单元的并行度不一样
- 支持片上动态的Launch和Sync
- 在NoC里面同时实现Launch控制,同步,数据流
- 统一在一个地方调度,所有单元并行,一起执行一个大的Graph Kernel
- 所有单元的指令特点:latency短且固定,只存在一级调度,调度后不可阻塞
- 高效的实现Launch和Sync,抽象出Fork/Join指令
- 精确的调用(launch)和同步带来的好处
- 突破内存墙:大算力->大延迟->大的in flight存储,大的pipeline存储,通过精密的同步和异步最小化存储器的使用
- 突破数据墙:越低的精度,需要的带宽比例越大,低精度算力面积呈指数下降,但是带宽需求是线性下降。只有精确的同步和调度才能最优化带宽资源的使用。
- 提升算力密度:算力单元的简化,静态化
- 大幅提升随机存取和计算的能力,是智能的重要指标
- 通过高效的控制和同步,最大化提高片上SRAM的复用率
- 总的片上的SRAM的容量很大,但是分散在很多小的L1,L1之间可以快速的同步数据,没有L2、LLC
- 分散的小的L1等价一个很大的cache,缓存下GEMM的整个右支
- 在有限的面积下,既满足了容量的需求,又满足了带宽的需求
- 支持非常细粒度的同步,比如 L1的各个bank之间的读写的同步,计算核的各个thread内的指令间同步,计算核内的各种Engine(ALU,RegRead)的同步,MALU的ld Cal St的同步。
- 动态graph,动态体现在动态launch,子图的动态的调度,循环调度,动态高效的同步支持,子图是完全静态的。
- 不同的算子需求下,都能写出高性能的算子,DSA的架构可能高性能,但是通用性差。完备指令架构很难做到优秀的PPA。gpu有强大的gs来适应大部分的不同数据流需求,simt的灵活调度提供充足的指令流,simi的指令尽量避免(软件解决)各种data和structure的hazard,减少流水线的复杂度。
- 通过紧密的同步控制,结合编译器,可以在通用性的前提下做到DSA的性能。通过减少流水线的fence需求,和硬件资源空泡的概率,特别是TensorALU、LD、ST等长latency的单元。传统的解决办法是通过多线程来提供充足的standby的微指令给硬件单元自己调度,避免空泡。

问题
- 支持多线程,为了充分利用硬件,不空泡
- 编程复杂
- 需要复杂的同步pipeline控制
- 需要复杂的编程L2L1复用
- 不支持多线程
- 通过graph指令,配合编译器,单线程实现并行
- 专用的加速指令,加速DMA操作,地址计算,同步/异步等
- DMA和NPU等外设,可以直接读取Scheduler的Inst SRAM的方式执行,避免配置参数拷贝
- 相对于scheduler的外设,通过fork和join到对应的外设来支持异步编程,避免复杂的多线程语义
- 物理上可以有超线程并行的硬件,共用一个线程的寄存器和堆栈,通过fork,join软件控制表达并行和依赖
- VMM怎么和VLD VST并行,pipeline
- kernel种类太多,体积大怎么办??
- 各个IP同步的开销太大
- HWSync硬件指令,同步资源集成到RISCV CPU里面去,独立的中断信号线
- 各个IP之间通过mailbox相互trigger,mailbox可以动态配置,但是像pipeline那样太复杂了,可以支持forkjoin抽象
- 数据的写透(fence),流水线都很长,导致leading tailing太大
- 每个NPU的任务都有一样的(明确的)leading和tailing时间,所以可以在scheduler直接流水发射
Graph Multiprocessor = GM
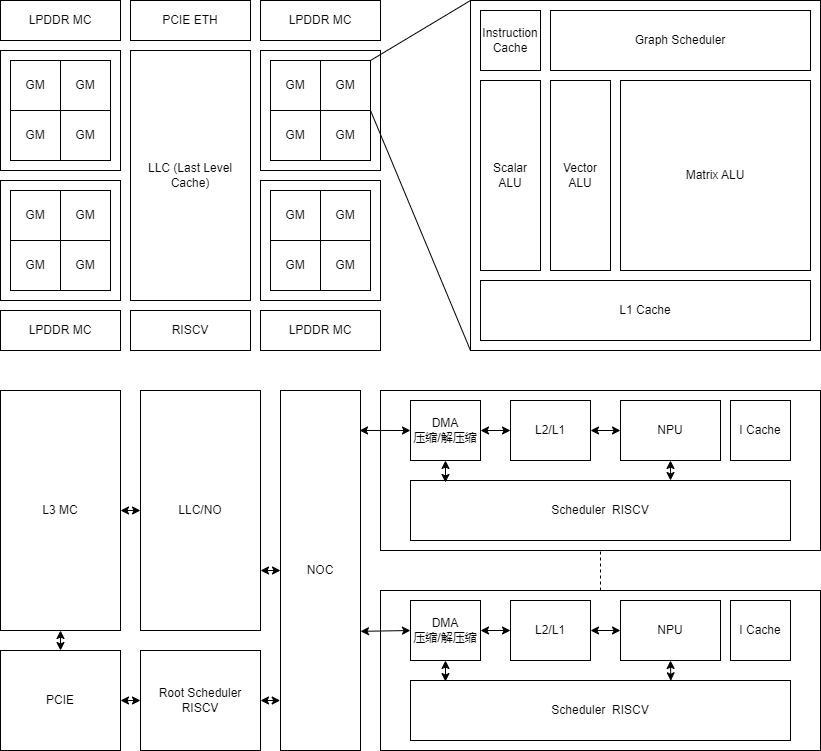
- 同一片代码多个并行传递参数问题
- fork支持参数的计算,批量fork自动累加传递的参数,类似于for功能的批量launch,
- 一个kernel最小的fork出来的执行单位表达类似于一个gemm指令
- 架构
- 32bit指令宽度
- 标量+向量+2D混合指令
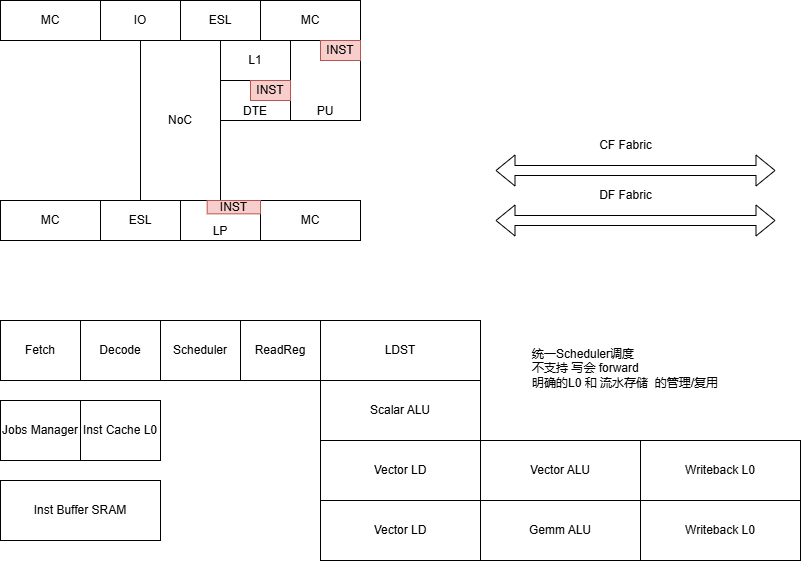
体系架构
- 支持未来的超动态网络?加速动态网络?
- 通过静态图的自动动态调度执行,能高效进行基于数据的动态网络
- 动态的launch/fork和join
- 编程的抽象
- SIMT的编程对象是一个thread,并且要求所有的任务拆解成一堆一样的thread
- GMP更像是MGMT,Multi Graph Multi Thread,编程的基本对象是Graph,Graph可大可小,可以组合,可以动态执行(Launch),可以被多个计算核并行加速
- 专用的fork/join指令和硬件记录graph的launch和结束
- 单个处理单元内部的不是多个线程free竞争run,而是经过编译器严格规划的,graph是processor运行的基本单元,graph内部的多个分支的并行需要精密的同步,
- 每个fork出来的subgraph对应的处理级别都是明确的,通过PU执行的graph,fork出来的subgraph,就是hw thread级别。
- 同步指令只能在同级别的graph之间进行?
- fork和join支持“无主模式”,fork出来之后主graph消失,每个子graph记住自己和哪些graph是并行的,利用这个信息进行同步,直到执行join之后,回到上一级graph,此时的join类似于barrier。
- counter : wait 指令总是等待自己的一个counter值,signal远程的一个counter值 ,怎么实现灵活动态的同步需求?
- 预先的pull一次,配置上动态wait信息,然后再wait signal
- 通过launch来指定动态同步信息
- 动态性是通过launch来体现的,动态信息是launch的时候统一生成的
- 一次launch出来的并行sub graph可以有一个graph group的信息资源,可以实现“signal下一个”功能,达到按序执行的调度目的
- 同步的指令都可以附带一个delay信息,因为静态的流水线,可以提前预估未来发生的同步点
- 同步指令不需要有状态信息,不需要读通用寄存器,不需要和其他有data hzd
- 大量的短的非stall的流水线 替代 少量的长的流水线,更多的非stall流水线有利于静态优化
架构
- Fork Join
- fork指令附带的信息
- 配置的代码段的参数
- 需要被join的信息
- 代码段的index
- 当前launch的编号ID:编号ID能直接解析出硬件的IP和memory mapping
- fork:专用于指令load的指令
- join指令的附带信息
- launch的编号ID
- fork指令附带的信息
- 向量寄存器VR L0.5 ,向量寄存器作为L0.5存在,所有的软件线程公用
- 向量寄存器VR L0,软件线程独立的寄存器,每个线程只有4个,直接设计在流水线上
- 张量寄存器TR L0.5 , 张量寄存器作为L0.5存在,所有的软件线程公用
- DTE支持transpose pad slice deslice
- PU单元内部的线程之间支持快速同步
- 线程内支持微架构的流水线操作和控制
-

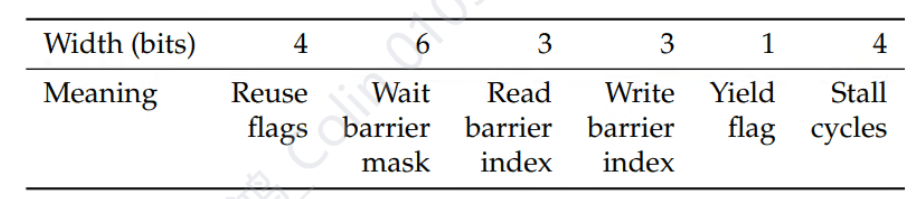
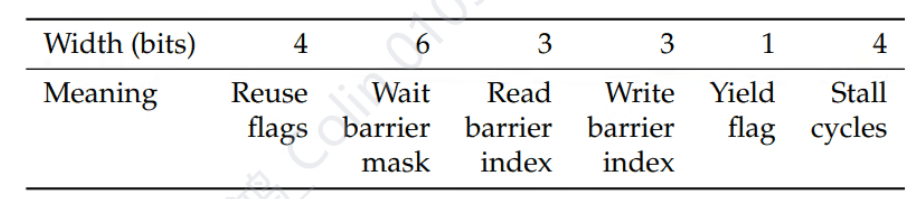
- Reuse flags 用于软件主动控制4个register的cache
- 6个barrier硬件资源用于软件主动创建thread之间的异步依赖关系(cuda的关键调度流水线长度是6),而不需要浪费硬件面积
-
- async_group 对历史的异步指令进行分组,以便灵活的进行同步
- async copy bulk 一个指令拷贝多个数据
- mbarrier:数据接受端支持主动维护数据传输状态,可以避免数据发起端频繁和接受端同步和fence来保证信号的前后顺序
- 所有的流水线的信息传递都因为有竞争,不能做无阻塞,常用的利用credit和valid/ready的阻塞方式,浪费太多的面积
- 本质上是硬件实现了某个程度的自动化的功能
- 如果能从软件角度就静态化,能节省大量的面积
- 从源头上(调度流水级)软件通过特殊指令控制发射的带宽来做到软流水无阻塞执行
产品架构
- 单个芯片die规模
- 4T int8算力
- 集成256MB DDR3 DRAM 1866 16bit 约3.7GB/s带宽
- 小规模的芯片,便于开发,降低风险和成本,便于仿真
- 支持无缝的拼接,多个芯片能容易组合成一个大的芯片,板级集成
- 降低流片成本,单个die非常小
- 降低封装成本,无需高级的芯片整合封装方案
- die to die 通过低成本的低速链接,不需要高速的serdes方案
ISA
ctrl
-
- Fork(code_index)
- launch
- Join()
Scalar
- scalar 计算