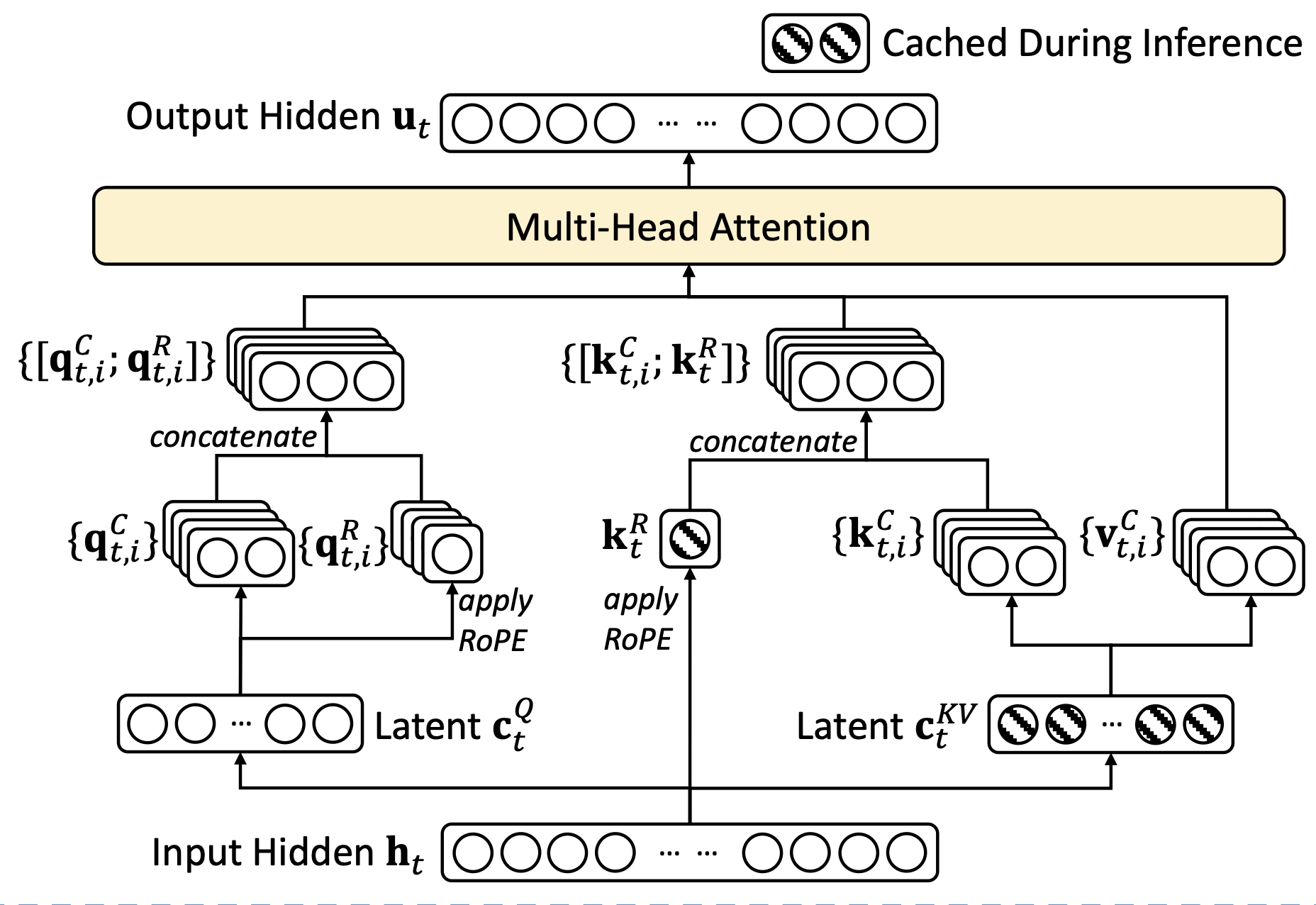
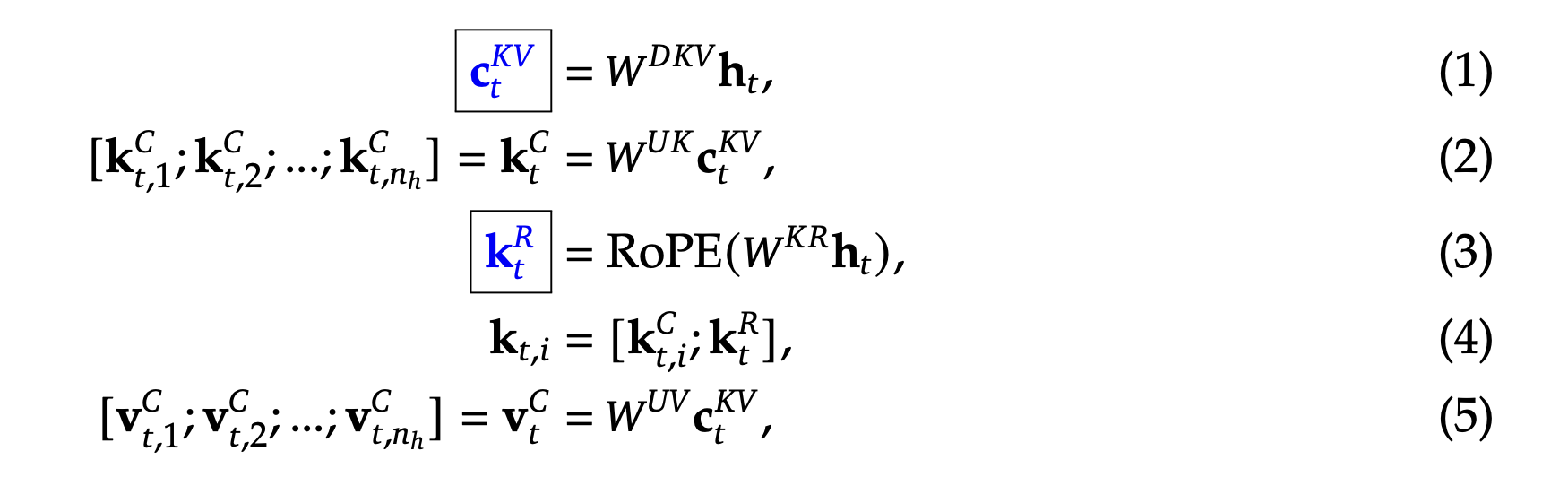MLA by Deekseek
- MLA 的核心思想是通过低秩联合压缩技术,减少 K 和 V 矩阵的存储开销
- 相对于传统的
相对于传统的MHA,主要引入了𝑊𝐷𝐾𝑉把htMHA,主要引入了 W^{DKV} 把 h_{t} 压缩了,并在推理时候缓存压缩后的数据,而不是kv,kv是使用WUV而不是 kv,kv 是使用 W^{UV}/WUK和CtKVW^{UK} 和 C_{t}^{KV} 恢复 - 可以被训练的参数有
WDKVW^{DKV}WUKW^{UK}WUVW^{UV}WKRW^{KR}