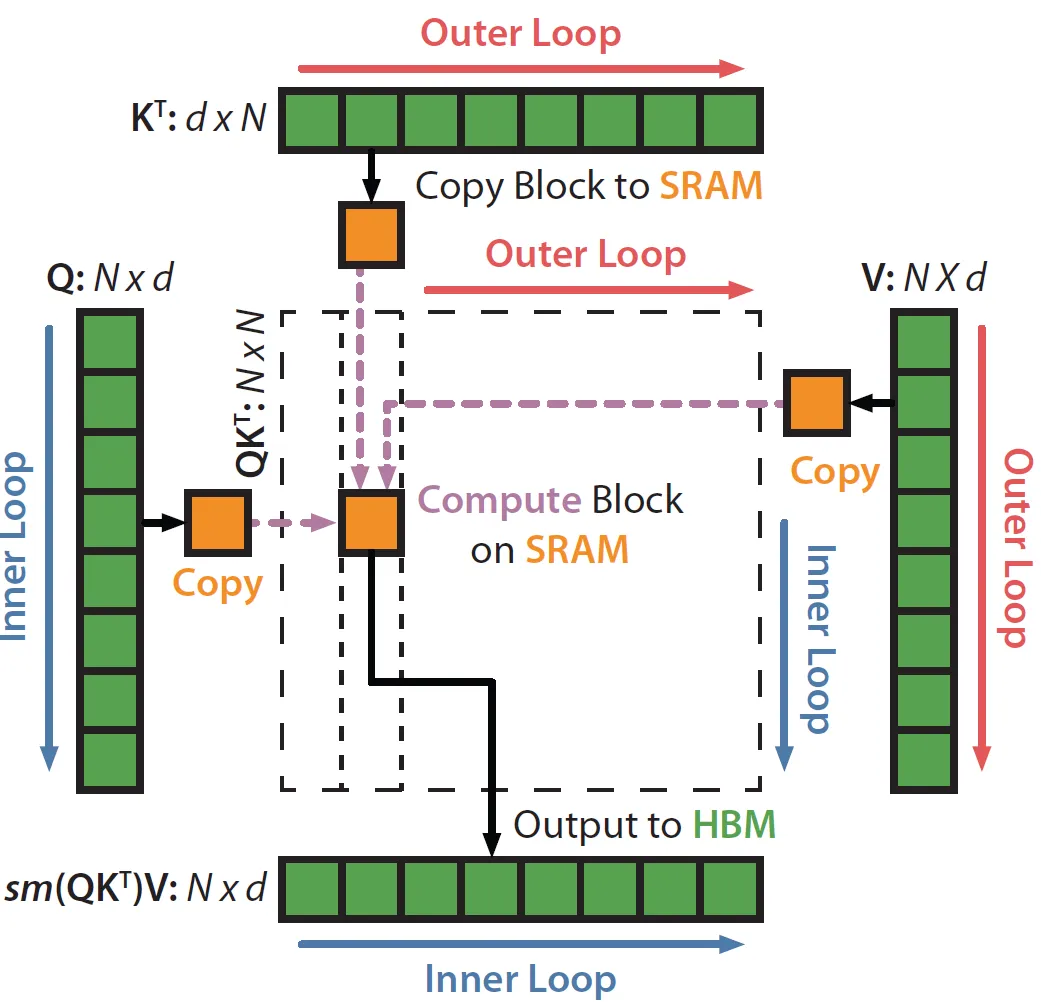
FlashAttention
Attention计算
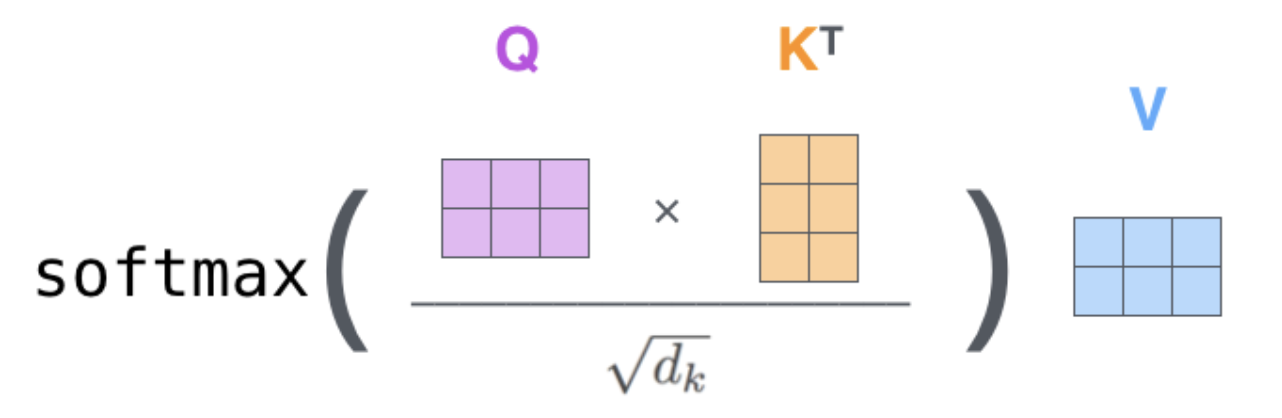
对一个Softmax计算的切片
def softmax(x):
x_max = x.max()
x_exp = torch.exp(x - x_max)
x_exp_sum = x_exp.sum()
return x_exp / x_exp_sum- 记录每个sub block的 softmax结果 + x_max(标量) + x_exp_sum(标量)
- 更新全局的 max(标量) 和 exp_sum(标量)
- 通过一次遍历elementwise计算,就可以修正局部softmax成全局softmax
- sum和max的分块计算避免了重复的数据读取进行统计
- exp指数的加减法操作可以通过exp指数乘除法逆操作
- sum的结果,可以通过乘除法修正分块的错误偏置
其中,步骤1可以在计算qk时候顺便计算,步骤3可以在计算v时候顺便计算,所以softmax结合qkv计算不浪费存储器的读写
原始softmax需要遍历3遍数据,1. 统计max,2.统计sum,3,除法
Flash Attention计算过程

- 1-5:主要在初始化和进行切分:
- 6-7:遍历K,V的每一块(Outer Loop)
- 8:遍历Q的每一块 (Inner Loop)
- 9:将分块后的QKV的小块加载到SRAM (Copy Block to SRAM)
- 10:计算Sij (Compute Block on SRAM)
- 11:计算Sij mask (Compute Block on SRAM)
- 12:计算当前块的m,l统计量 (Compute Block on SRAM)
- 13:更新全局m,l统计量 (Compute Block on SRAM)
- 14:dropout (Compute Block on SRAM)
- 15:计算Oi并写入HBM (Output to HBM)
- 16:把li,mi写入HBM (Output to HBM)