Transformer研究
- Transformer解析
- KV Cache
- ChatGLM3典型计算图
- Tokenization
- Transformer in CV
- 新方法
- Attention是不是必须的
- 神经网络的逻辑
- 改进大规模训练稀疏自编码器的方法
- Transformer NLP到底有没有智能?
- 用推理的临时态实现意识--CoT
Transformer解析
- 精细的抽象,记忆空间特别大
- 在nlp问题里面,通过逐个处理新的token,递归得进行抽象
欠缺
- 记忆和人类不一致,而且没有统一的表达,不通用
- 没有自主意识,还是在算概率,逃不开数学上的特征分割,虽然不能证明当前的数学基础、梯度下降是错误的,但是AGI肯定不是只有这些,AGI更多的是一种复杂的工程,而不是简单几个公式
- Transformer架构个在处理长上下文时,会受到二次复杂度(浪费算力),以及长度外推能力弱的限制。
KV Cache

https://zhuanlan.zhihu.com/p/662498827
ChatGLM3典型计算图
## data flow
```
query -> "你好"
|
tokenizer -> input_ids [6]
|
rotary_pos_emb embedding -> [1, 6, 4096]
\ /
GLMBlock x 28 -> [6, 1, 4096] <---|
RMSNorm -> [6, 1, 4096] | final_layernorm
[-1:] -> [1, 1, 4096] |
Linear -> [1, 1, 65024] | output_layer 4096->65024
softmax -> [1, 65024] |
multinomial -> [1] |
cat([input_ids, next_tokens]) ---|
↓
tokenizer.decode( )
# GLMBlock
input
/ \
/ RMSNorm hidden_states -> [6, 1, 4096]
| | / \
| | | pow(2) -> [6, 1, 4096]
| | | |
| | | mean -> [6, 1, 1]
| | | ↓
| | | rsqrt( + eps) -> [6, 1, 1]
| | \ /
| | mul -> [6, 1, 4096]
| | \ weight -> [4096]
| | \ /
| RMSNorm mul -> [6, 1, 4096]
| \
| SelfAttention x -> [6, 1, 4096]
| | |
| | Linear -> [6, 1, 4608] 4096->4608
| | / | \
| | q k v [6, 1, 32, 128] [6, 1, 2, 128] [6, 1, 2, 128]
| | / | \
| | pos_emb pos_emb \ -> cat( x0*y0-x1*y1, x1*y0-x0*y1, x, y)
| | | | |
| | | expand expand -> [6, 1, 32, 128] [6, 1, 32, 128]
| | permute permute permute -> [1, 32, 6, 128] [1, 32, 6, 128] [1, 32, 6, 128]
| | \ / |
| | |---- matmul | -> [1, 32, 6, 128] [1, 32, 128, 6] -> [1, 32, 6, 6]
| | | add(mask) / -> [1, 32, 6, 6]
| | attention| softmax / -> [1, 32, 6, 6] dim:-1
| | | \ /
| | |---- matmul -> [1, 32, 6, 6] [1, 32, 6, 128] -> [1, 32, 6, 128] -> [6, 1, 4096]
| SelfAttention Linear -> [6, 1, 4096] 4096->4096
| /
| dropout
\ /
Add
/ \
| RMSNorm hidden_states -> [6, 1, 4096]
| | / \
| | | pow(2) -> [6, 1, 4096]
| | | |
| | | mean -> [6, 1, 1]
| | | ↓
| | | rsqrt( + eps) -> [6, 1, 1]
| | \ /
| | mul -> [6, 1, 4096]
| | \ weight -> [4096]
| | \ /
| RMSNorm mul -> [6, 1, 4096]
| /
| mlp /
| | Linear -> [6, 1, 27392] 4096->27392
| | / \
| | chunk1 chunk0 -> [6, 1, 13696]
| | | | \
| | | | sigmoid
| | | | /
| | | mul
| | \ /
| | mul -> [6, 1, 13696]
| mlp Linear -> [6, 1, 4096] 13696->4096
| /
| dropout
| /
Add
```
Tokenization
注:作为术语的“tokenization”在中文中尚无共识的概念对应,本文档采用英文表达以利说明。
Qwen-7B采用UTF-8字节级别的BPE tokenization方式,并依赖tiktoken这一高效的软件包执行分词。
Qwen-7B中有两类token,即源于BPE、bytes类型的普通token和特殊指定、str类型的特殊token。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('Qwen/Qwen-7B', trust_remote_code=True)
普通token
普通token源于BPE,是在UTF-8编码的文本字节序列上学习得到的。
尽管基于字节序列的方式保证了所有文本均可被tokenize且没有未登录token问题,但处理罕见文本时有可能回退到字节级别的编码。
由于从字节序列解码为文本时,errors参数设为replace,处理不完整的token序列可能会遇到UTF-8解码错误,表象是生成中包含“替换字符”(�)。
这一行为可以通过将errors参数设为ignore来规避。
一次性修改可以传入tokenizer的decode函数,持久性修改可以传入tokenizer的初始化函数,请注意decode的配置优先级更高。
errors的可选值,请参阅Python文档.
>>> tokenizer.decode([51461])
' �'
>>> tokenizer.convert_ids_to_tokens([51461])
[b' \xe6\xa0']
>>> b' \xe6\xa0'.decode("utf-8", errors='replace')
' �'
>>> tokenizer.decode([51461, 117])
' 根'
>>> tokenizer.convert_ids_to_tokens([51461, 117])
[b' \xe6\xa0', b'\xb9']
>>> b' \xe6\xa0\xb9'.decode("utf-8", errors='replace')
' 根'
bytes类型的普通token到id的映射可以通过tokenizer.get_vocab()获取。
尚不支持也不推荐向tokenizer增加普通token。
特殊token
特殊token用以给模型传递特殊信号,如到达文本末尾。
理论上,输入文本中不包含特殊token,它们仅在tokenization后由开发者手动加入。
特殊token的字面表达,如表示文本结束的<|endoftext|>,仅便于指代特殊token,不意味着它们在输入文本空间中。
目前,训练中使用的、已经有固定含义的、不应做它用的特殊token,Qwen-7B中有<|endoftext|>,Qwen-7B-Chat中有<|endoftext|>、<|im_start|>以及<|im_end|>。
但词表中也留有供扩展的特殊token位,可用<|extra_0|>到<|extra_204|>来指代。
str类型的特殊token字面表达到id的映射,可以通过tokenizer.special_tokens获取。
对于提供的模型参数(Qwen-7B和Qwen-7B-Chat)而言,诸如bos、eos、unk、pad、mask、sep等的特殊token的概念并不适用。
特例是pad,由于这个token理论上并不参与模型计算,所以可以使用任意token表达这一概念。
但保险起见,目前可在tokenizer初始化时设定的特殊token,仅可使用已知的特殊token字面表达,即<|endoftext|>、<|im_start|>、<|im_end|>和<|extra_0|>到<|extra_204|>。
对于微调或者其它需要这些token才能运行的框架,可以如下配置
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('Qwen/Qwen-7B', trust_remote_code=True, pad_token='<|endoftext|>')
注意: 对于提供的训练好的模型,设置诸如
bos、eos、unk之类的没有意义,即模型不需要这些概念。 如果设置了这些token,但没有相应的微调这些token以让模型理解其含义,未知行为可能被触发。 特别时,不应混淆<|endoftext|>和eos的概念,除非应用场景中它们的实际含义是一致的,即句子末尾等价于文本末尾。
注入攻击防御
由于特殊token和普通token概念上的差异,如果输入文本中含有特殊token的字面表达该如何处理? 以下面文本为例
print("<|endoftext|>")
其正确的tokenization为
ids:[1350, 9639, 91, 8691, 723, 427, 91, 82598]
tokens: [b'print', b'("<', b'|', b'endo', b'ft', b'ext', b'|', b'>")']
不是
ids: [1350, 445, 151643, 899]
tokens: [b'print', b'("', '<|endoftext|>', b'")']
默认行为曾是正确的,即输入文本中任何字符一律按普通token处理,特殊token应由开发者在tokenization人工处理。 然后,这与社区中的实践似有差异,为开发者复用代码增加了额外适配步骤。
默认行为已被调整为从输入文本中解析特殊token的字面表达。
如需启用注入攻击防御,请传入参数allowed_special=set():
>>> tokenizer('print("<|endoftext|>")', allowed_special=set())
{'input_ids': [1350, 9639, 91, 8691, 723, 427, 91, 82598], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1]}
这一行为可以更精细的调控,将allowed_special设计为str的集合即可:
>>> tokenizer('print("<|extra_0|>")<|endoftext|>', allowed_special={'<|endoftext|>'})
{'input_ids': [1350, 9639, 91, 15460, 62, 15, 91, 82598, 151643], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
如果希望输入中遇到特殊token的字面表达时,获得更直接的提醒,通过配置disallowed_special可以让tokenizer直接触发异常:
>>> tokenizer('print("<|extra_0|>")<|endoftext|>', allowed_special={'<|endoftext|>'}, disallowed_special=('<|extra_0|>', ))
...
ValueError: Encountered text corresponding to disallowed special token '<|extra_0|>'.
If you want this text to be encoded as a special token, pass it to `allowed_special`, e.g. `allowed_special={'<|extra_0|>', ...}`.
If you want this text to be encoded as normal text, disable the check for this token by passing `disallowed_special=(enc.special_tokens_set - {'<|extra_0|>'})`.
To disable this check for all special tokens, pass `disallowed_special=()`.
更多关于allowed_special和disallowed_special的信息, 请参阅tiktoken代码.
新的默认行为与以下设定等价
>>> tokenizer('print("<|endoftext|>")', allowed_special="all", disallowed_special=())
{'input_ids': [1350, 445, 151643, 899], 'token_type_ids': [0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1]}
词表扩展
特别提醒:请仔细阅读本部分的说明,理解每一步操作,并承担可能的后果。 由于词表扩展部分由您提供,产出方式的差异可能导致特定的不兼容情况,请审慎操作。
Qwen系列模型的tokenizer基于BPE方案提取文本中的token。 从UTF-8编码的字节开始(每个字节都可以是一个token),两两token合并成为新token,直至不能再合并出新的token为止。 由于词表同时还记录了token的合并方式,直接向词表中添加词可能对Qwen的tokenizer并不适用,即通过已有的token可能合并不出来您添加词。
因而,请参照以下步骤获得合并信息:
-
准备一个纯文本文件,例如名为
qwen_extra_vocab.txt,每行一个待添加的词和它的频率,中间用制表符\t分隔。以下是一个文件的例子:
我是一只猫 20 你是一只猫 10 他是一只猫 5 一只 200 一只猫 100 夸张的 比喻手法 20频率是必需的,用来计算合并的优先级。
-
准备基础的词表文件,例如
qwen.tiktoken,并确认新加入token的起始索引。Qwen模型词表中有151,643个普通token,有208个特殊token。 简单起见,起始索引可以设置为151,851(默认值)。 您可以覆写不起效的特殊token,但您需要相应的修改tokenizer代码。
-
运行以下命令:
python add_merges.py qwen.tiktoken qwen_extra.tiktoken qwen_extra_vocab.txtadd_merges.py代码在GitHub存储库中。 基于提供的qwen_extra_vocab.txt,该脚本将学习新的token合并方式。 新token及其索引将存储在qwen_extra.tiktoken文件中。 您可以视情况修改有关路径。由于是纯Python实现,如果您添加了非常多的词,预期会花费较多时间。
请注意,由于预切分,有些词是无法作为token加入的。 如果您添加了这些词,您会收到警告:
WARNING - 夸张的 比喻手法 would be pre-tokenized to ['夸张的', ' 比喻手法'], and thus cannot be added to vocabulary WARNING - word 一只 is already a token b'\xe4\xb8\x80\xe5\x8f\xaa', skipping INFO - number of existing merges: 151643 INFO - number of words for expanding: 4 DEBUG - (b'\xe4\xb8\x80\xe5\x8f\xaa', b'\xe7\x8c\xab') (一只猫) is selected as the next merge with freq 100 DEBUG - (b'\xe5\x8f\xaa', b'\xe7\x8c\xab') (只猫) is selected as the next merge with freq 35 DEBUG - (b'\xe6\x98\xaf\xe4\xb8\x80', b'\xe5\x8f\xaa\xe7\x8c\xab') (是一只猫) is selected as the next merge with freq 35 DEBUG - (b'\xe6\x88\x91', b'\xe6\x98\xaf\xe4\xb8\x80\xe5\x8f\xaa\xe7\x8c\xab') (我是一只猫) is selected as the next merge with freq 20 DEBUG - (b'\xe4\xbd\xa0', b'\xe6\x98\xaf\xe4\xb8\x80\xe5\x8f\xaa\xe7\x8c\xab') (你是一只猫) is selected as the next merge with freq 10 DEBUG - (b'\xe4\xbb\x96', b'\xe6\x98\xaf\xe4\xb8\x80\xe5\x8f\xaa\xe7\x8c\xab') (他是一只猫) is selected as the next merge with freq 5 INFO - number of newly learned merges: 6
qwen_extra.tiktoken会包含以下内容:
5LiA5Y+q54yr 151851
5Y+q54yr 151852
5piv5LiA5Y+q54yr 151853
5oiR5piv5LiA5Y+q54yr 151854
5L2g5piv5LiA5Y+q54yr 151855
5LuW5piv5LiA5Y+q54yr 151856
您可以按如下方式使用扩展后的词表:
from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-7B", trust_remote_code=True, extra_vocab_file="qwen_extra.tiktoken")
>>> len(tokenizer)
151857
>>> tokenizer("我是一只猫")
{'input_ids': [151854], 'token_type_ids': [0], 'attention_mask': [1]}
注意:您需要使用2023年10月8日后的tokenizer代码才能传递extra_vocab_file参数。如是其它情况,您可以将qwen_extra.tiktoken内容复制粘贴到qwen.tiktoken内容后面。
您需要微调模型才能使新的token发挥作用。
注意事项
Qwen的tokenizer是直接从UTF-8编码的字节序列开始处理的,这与其它tokenizer比如SentencePiece是很不一样的。SentencePiece是从Unicode码位(可以理解为一个字符)开始处理,遇到未登录的再用UTF-8编码成字节。 从字节开始的一个潜在问题是如果频率信息不够准确,比如频率信息是在很少数据上统计得到的,Unicode码位按UTF-8编码成字节后的边界可能会出现差错。 理论上,如果模型微调数据量不足,使用扩展后的词表也可能出现意外问题。
举个例子(非实际情况),对于一只的UTF-8字节序列b'\xe4\xb8\x80\xe5\x8f\xaa',中间两个字节b'\x80\xe5'可能会先合并为一个token,跨越了一(b'\xe4\xb8\x80')和只(b'\xe5\x8f\xaa')的码位边界。
这对于已登录token不会有什么影响(最后总会合并为一只),但对于未登录的,可能会产生一些不同寻常的合并/token。
这些token序列可能对于预训练模型是陌生的。
我们的建议是保险起见,您最好先收集待添加词中的所有Unicode码位,然后单独指定它们的频率大于其所构成词的频率之和。 不过由于Qwen的tokenizer已包含了大多数中文字,对于中文词的话,不添加中文字的频率,大部分情况下是可行的。
您可能已经发现了,在提供的例子中,一只已经是登录过的token了,但只猫还是学习成为了一个新token,出现了“交叉”。
原因是在Qwen中是一也是一个已知token,且其频率/优先级比一只要高,因而对于是|一|只|猫这个片段,合并的次序是是一|只|猫 -> 是一|只猫 -> 是一只猫(省略UTF-8字节级别的合并)。
这是常规BPE的特性,其完全基于分布,并不知道哪些字节可以构成合法的Unicode码位、合法的字符或是词。
副产物是一段文本在不同的上下文下可能会有不同的tokenize结果,对于仅包含ASCII字符的文本同样如此。
>>> tokenizer.tokenize("Panda")
[b'P', b'anda']
>>> tokenizer.tokenize(" Panda")
[b' Panda']
>>> tokenizer.tokenize("Pandas")
[b'P', b'andas']
>>> tokenizer.tokenize(" Pandas")
[b' Pand', b'as']
这仅说明在用于学习BPE的数据中,这样的组合是更高频的。 如果您有海量的训练语料,这并不会是个问题。
Transformer in CV
MEGALODON
https://arxiv.org/pdf/2404.08801.pdf
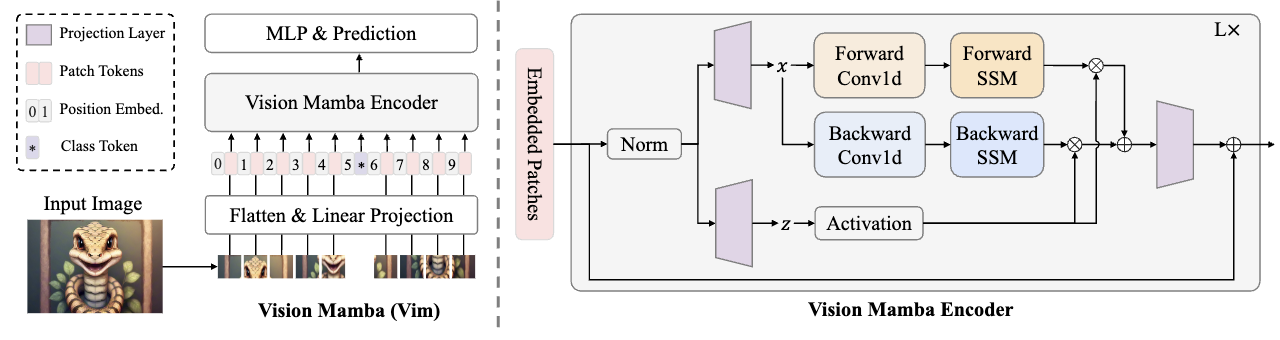
Vision Mamba
https://github.com/hustvl/Vim/
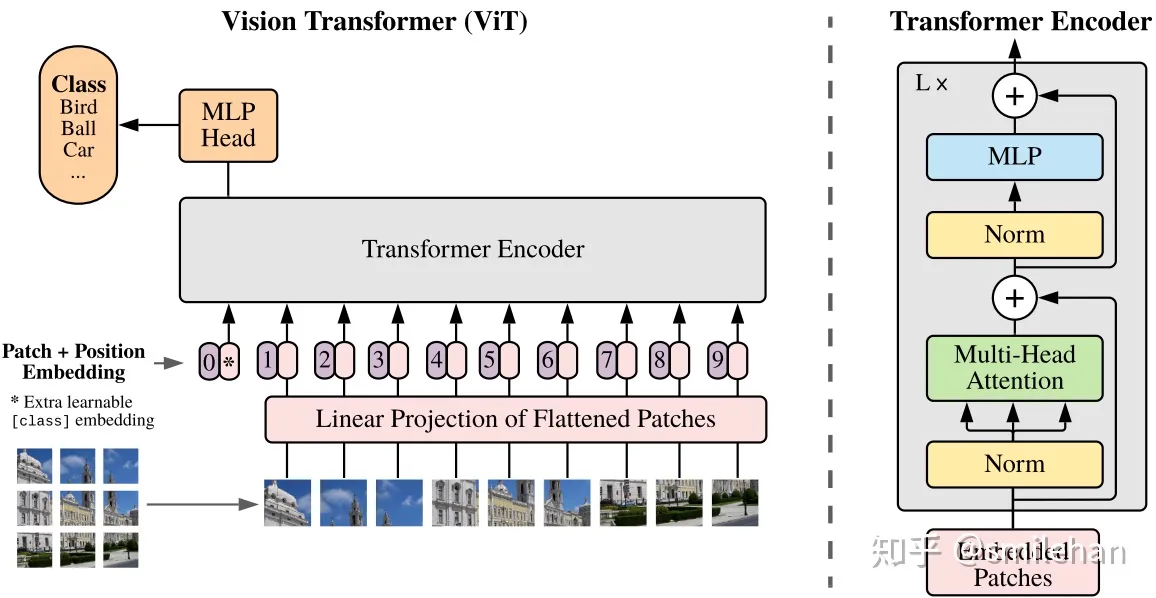
Vision Transformer,ViT
https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/vision_transformer.py
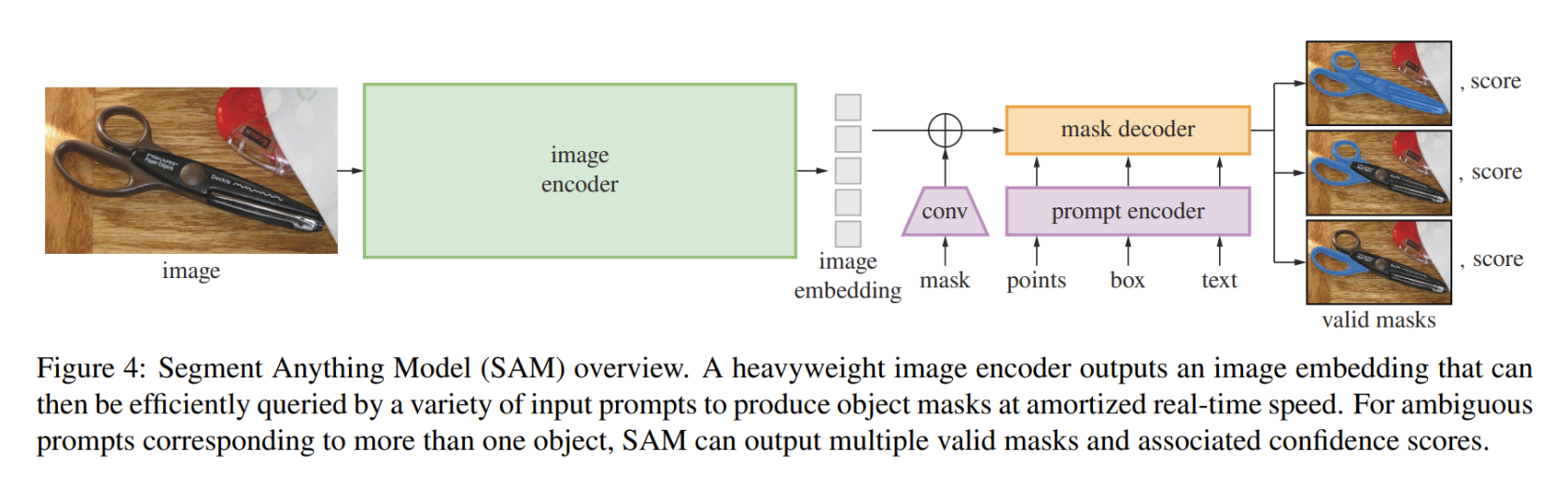
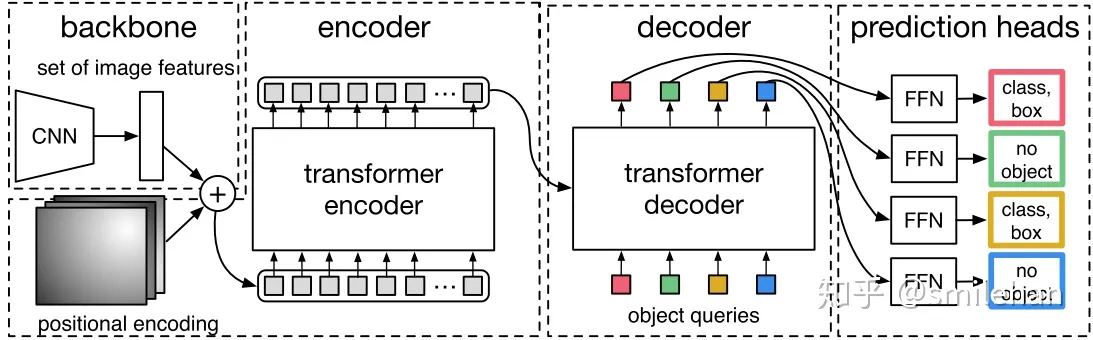
DEtection TRansformer,DETR
SEgmentation TRansformer,SETR
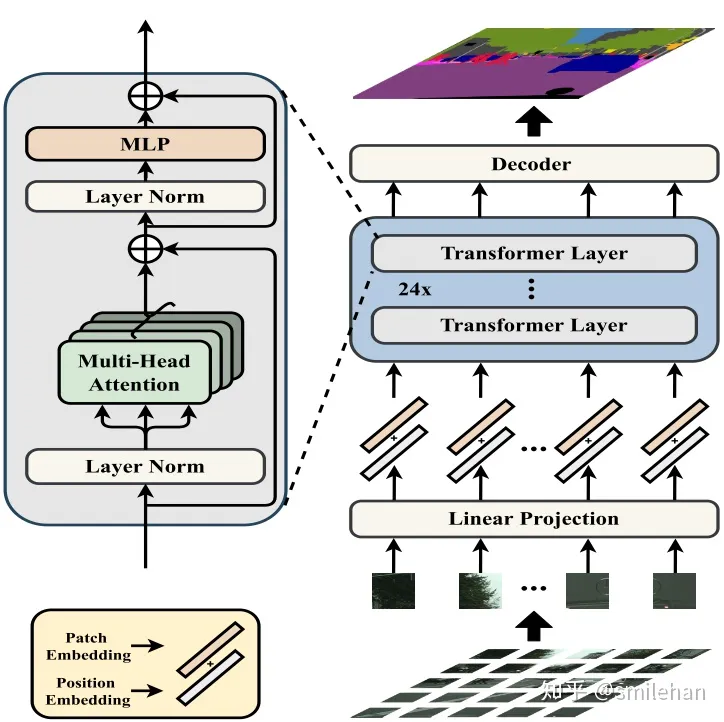
新方法
Llama 3
- 128K token 的分词器,这种分词器在编码语言时更加高效,这使得模型的性能得到了显著提升
- 分组查询注意力(GQA)技术
- 在训练过程中,我们让模型处理最多 8,192 个 Token 的序列,并巧妙地使用掩码技术来确保模型的自注意力机制不会跨越不同文档的界限,从而保证了模型的准确性和效率。
- 训练集规模扩大了七倍,代码数据量也增加了四倍
- 我们设计并实施了一系列先进的数据过滤流程。这些流程包括应用启发式过滤器、NSFW 内容过滤、语义去重技术和文本质量分类器等,用以预判数据的优劣。我们利用 Llama 2 来生成用于 Llama 3 的文本质量分类器的训练集。对这些数据的仔细策划,并且对人类标注者提供的标准进行了多轮质量保证。
- 我们采用了三种并行化技术:数据并行、模型并行和流水线并行。在 16K 个 GPU 上同时训练时,我们的最高效实现方式能够达到每个 GPU 超过 400 TFLOPS 的计算利用率。我们还特别构建了两个 24K GPU 的集群来进行模型训练。
- 我们开发了一套先进的训练栈,它能够自动进行错误检测、处理和维护。硬件和系统的可靠性
- 我们的后训练策略融合了监督式微调(SFT)、拒绝抽样、近端策略优化(PPO)和直接策略优化(DPO)等多种技术。在 SFT 中使用的提示质量以及 PPO 和 DPO 中使用的偏好排名对于提升模型的性能至关重要。通过对这些数据进行精细筛选和对人类标注者提供的内容进行多轮质量审核,我们实现了模型质量的重大提升。
Infini-Transformer
Infini-attention的核心思想是将压缩记忆(compressive memory)整合到传统的注意力机制中,从而使得基于Transformer的语言模型能够高效处理无限长的输入序列,同时保持内存和计算资源的有界性。这一思想的主要特点和创新点包括:
- 压缩记忆的引入:Infini-attention通过引入压缩记忆系统,使得模型能够在处理长序列时保持固定的参数数量,而不是随着输入长度的增加而线性增长。这种记忆系统通过改变其参数来存储和回忆信息,从而实现了对长期依赖的有效捕捉。
- 结合局部和全局注意力:Infini-attention在单个Transformer块中同时构建了局部(masked local)注意力和长期(long-term linear)注意力机制。局部注意力负责处理当前输入段内的上下文信息,而长期注意力则从压缩记忆中检索历史信息,两者结合提供了对长距离依赖的有效建模。
- 高效的参数重用:在Infini-attention中,标准注意力计算中的键(key)、值(value)和查询(query)状态被重用于长期记忆的整合和检索。这种重用策略不仅提高了参数效率,还加速了模型的训练和推理过程。
- 流式处理能力:Infini-attention支持对输入序列进行流式处理,这意味着模型可以逐步处理和推理新输入的数据,而不需要一次性处理整个序列。这对于处理实时数据流或非常长的文本序列尤其有用。
- 持续预训练和任务适应:Infini-attention设计上支持持续的预训练和针对长上下文的适应,使得模型可以通过持续学习来提高对长序列的处理能力,并且可以通过任务特定的微调来适应不同的应用场景。
总之,Infini-attention的核心思想是通过压缩记忆和注意力机制的结合,实现对长序列数据的有效处理,同时保持计算和内存效率,这对于推动大型语言模型在各种长文本处理任务中的应用具有重要意义。
LNNs具备两个核心特点
动态架构和持续学习与适应性。
动态架构让LNNs的神经元比传统神经网络更具表现力,从而提高了模型的可解释性。
而持续学习与适应性则使LNNs能够在训练后继续适应变化的数据,这一点更接近生物大脑的工作机制。
相较于传统神经网络,LNNs展现出多重优势。它们不需要大量的标记训练数据就能产生准确的结果,而且模型规模较小,计算需求较低,这使得它们在企业级应用中具有很好的可扩展性。
此外,LNNs对输入信号中的噪声和干扰也表现出更强的鲁棒性。
总的来说,液体神经网络作为一种有前景的神经网络方法,能够出色地处理复杂的实时数据处理任务,并具备良好的适应性,因此在多种应用中都能成为有价值的工具。
Attention是不是必须的
RNN容易梯度消失:梯度消失的本质问题是,网络太深了,这里的深代表信息表达的层级而不是拓扑,resnet就是解决这个问题
Transformer 的强大之处同时也是它的弱点:Transformer 中固有的自注意力机制(attention)带来了挑战,主要是由于其二次复杂度造成的,这种复杂度使得该架构在涉及长输入序列或资源受限情况下计算成本高昂且占用内存。
非Transformer 技术研究
- 以 RWKV、 Mamba 和 S4 为代表,它们完全用 recurrent(循环)结构去替代 attention。这种思路是用一个固定的内存记住前面的信息,但目前看来虽然可以记住一定长度,但要达到更长的长度是有难度的。
- 把 full attention 这种密集结构变得稀疏,例如 Meta 的 Mega,在之后的计算中不再需要算所有 attention 矩阵中的每一个元素,模型效率也随之变高。
DeepMind 团队提出的 Hawk 和 Griffin 同样认为没有 attention 是不行的,属于 gated linear RNN,跟 Mega 一样属于混合模型。
现阶段来看,基于现有硬件的算力基础,用Transformer 去做端侧大模型的难度很高,还是需要在云上完成计算推理等工作,而且应答速度不如人意,终端用户很难接受。
上述投资人评价 RWKV “麻雀虽小,五脏俱全”,总体体验感能达到 GPT-3.5 的 60 分,但并不知道最后能否达到 GPT 的 80 分、90 分。这也是非Transformer 的问题所在,即如果舍弃了框架的复杂度、可能会牺牲上限的天花板。
Transformer 日益坚固的生态护城河,无论是硬件、系统、应用,都是围绕Transformer 做适配、优化,使得开发其他架构的性价比降低,导致想要开发新的架构越来越难。
Attention的加速TopK Attention的问题
众所周知,注意力机制本质上具有稀疏性,因此动态稀疏注意力和基于TopK的近似方法得到了广泛研究。
然而,这些方法往往伴随着显著的质量下降问题。
目前已有的KV缓存压缩技术,如Quest、H2O和Loki,主要通过筛选出KV缓存中注意力得分最高的子集来提高效率。然而,尽管这些方法在实践中表现出一定的效果,基于TopK的注意力依然是一种存在偏差的近似方法,且缺乏理论上的严格保障。
这种不足限制了其在高精度场景中的广泛应用。
神经网络的逻辑
量化
量化不是没有代价。Llama3模型的量化效果比Llama2模型要差,量化过程中的质量损失更大。
直觉是,一个训练不足的模型受到量化的影响较小,因为其训练过程并没有充分利用每一个权重。关于Llama的一个关键发现,以及它为何能在其大小范围内表现出色,是因为它们在比文献中所谓的“最佳”状态更大的数据集上训练了更长时间。
综合这些因素,似乎可以得出以下结论:小型模型、大量数据、长时间训练>大型模型+量化。基本上,量化是一种用于缩短长时间训练的损失性的捷径。数据的数量和质量,一如既往是所有这些中最重要。
首先,研究人员发现大语言模型的Hessian矩阵表现出极端的长尾分布特性。这也意味着大多数位置权重的变化对模型的输入输出并不敏感,而少部分元素对于权重的输出非常敏感。其次,大语言模型中的权重密度遵循不均匀的钟形分布形式。
用 数据精度限制的特性直接替代Softmax
Batch Normalization
BN使得结果(输出信号各个维度)的均值为0,方差为1。为了防止“梯度弥散”
- 可以使用更大的学习率,训练过程更加稳定,极大提高了训练速度。
- 可以将bias置为0,因为Batch Normalization的Standardization过程会移除直流分量,所以不再需要bias。
- 对权重初始化不再敏感,通常权重采样自0均值某方差的高斯分布,以往对高斯分布的方差设置十分重要,有了Batch Normalization后,对与同一个输出节点相连的权重进行放缩,其标准差𝜎也会放缩同样的倍数,相除抵消。
- 对权重的尺度不再敏感,理由同上,尺度统一由𝛾参数控制,在训练中决定。
- 深层网络可以使用sigmoid和tanh了,理由同上,BN抑制了梯度消失。
- Batch Normalization具有某种正则作用,不需要太依赖dropout,减少过拟合。
激活函数
非线性激活函数对于神经网络容量至关重要,没有它们,神经网络只是大型因式分解线性模型。研究结果表明,ReLU显著增强了模型的容量。虽然它最初的作用是为了减轻梯度的消失和爆炸,但ReLU还提高了网络的数据拟合能力。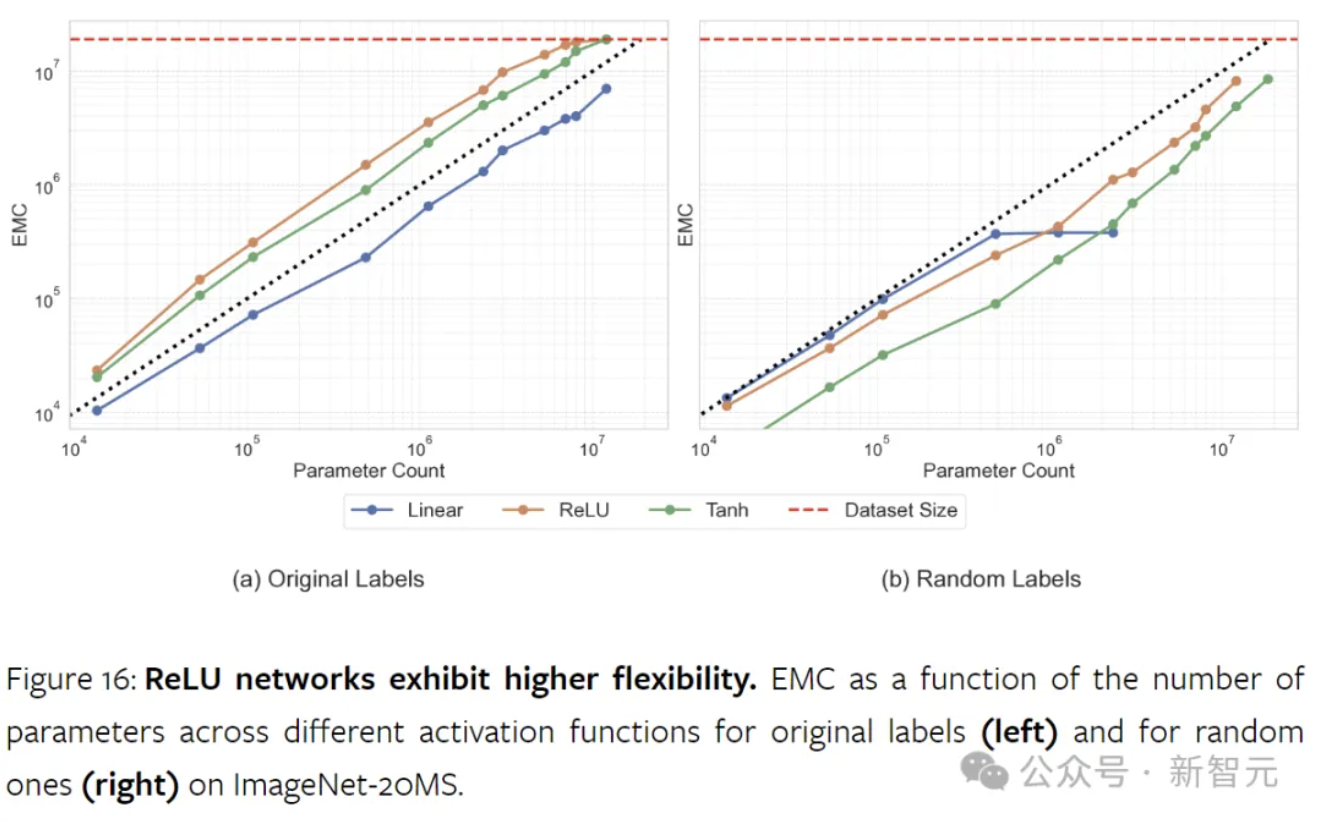
- Sigmoid
- 软饱和性,容易产生梯度消失,导致训练出现问题
- 是不是不同层使用不用的激活函数?越初层,信息绝对性越差,不能使用sigmoid
- 输出不是以0为中心
- 软饱和性,容易产生梯度消失,导致训练出现问题


- tanh
- 和sigmoid一样存在梯度消失的问题


- RELU
- 收敛得更快
- 计算简单,计算快
- 会造成神经元死亡,比如输出总是0,不可逆得死亡了
- 可能是因为在0附近得不连续
改进大规模训练稀疏自编码器的方法
Ref :https://mp.weixin.qq.com/s/iZHPnnIncVFa8QJOuH8qFg
神经网络中的激活通常表现出不可预测和复杂的模式,且每次输入几乎总会引发很密集的激活。而现实世界中其实很稀疏,在任何给定的情境中,人脑只有一小部分相关神经元会被激活。
研究人员开始研究稀疏自编码器,这是一种能在神经网络中识别出对生成特定输出至关重要的少数“特征”的技术,类似于人在分析问题时脑海中的那些关键概念。
在OpenAI超级对齐团队的这项研究中,他们推出了一种基于TopK激活函数的新稀疏自编码器(SAE)训练技术栈,消除了特征缩小问题,能够直接设定L0(直接控制网络中非零激活的数量)。
具体来看,他们使用GPT-2 small和GPT-4系列模型的残差流作为自编码器的输入,选取网络深层(接近输出层)的残差流,如GPT-4的5/6层、GPT-2 small的第8层。
并使用之前工作中提出的基线ReLU自编码器架构,编码器通过ReLU激活获得稀疏latent z,解码器从z中重建残差流。损失函数包括重建MSE损失和L1正则项,用于促进latent稀疏性。
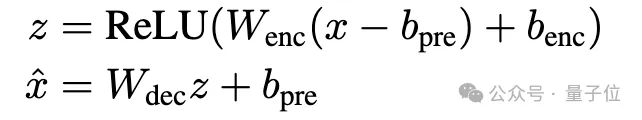
然后,团队提出使用TopK激活函数代替传统L1正则项。TopK在编码器预激活上只保留最大的k个值,其余清零,从而直接控制latent稀疏度k。
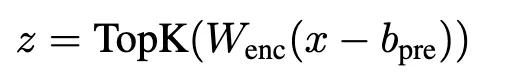
不需要L1正则项,避免了L1导致的激活收缩问题。实验证明,TopK相比ReLU等激活函数,在重建质量和稀疏性之间有更优的权衡。
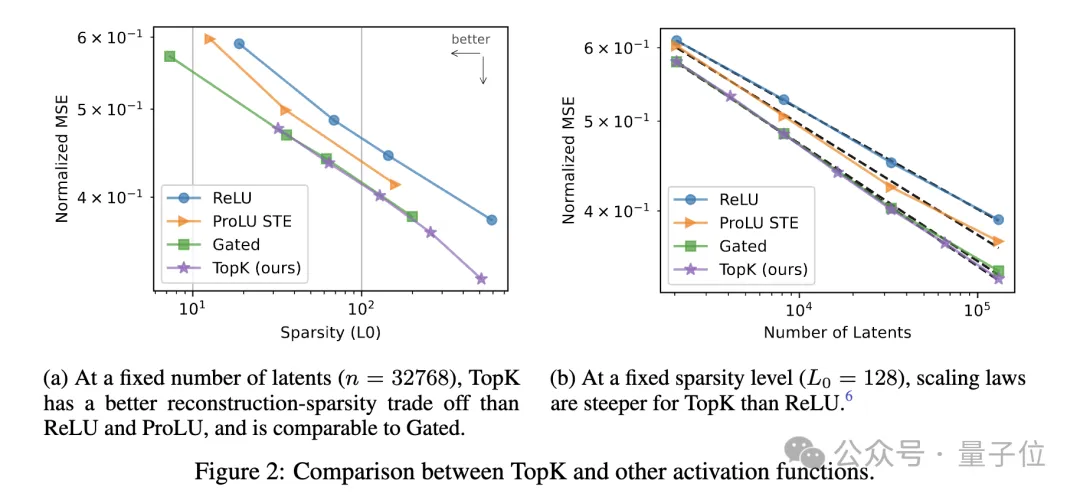
此外,自编码器训练时容易出现大量latent永远不被激活(失活)的情况,导致计算资源浪费。
团队的解决方案包括两个关键技术:
-
将编码器权重初始化为解码器权重的转置,使latent在初始化时可激活。
-
添加辅助重建损失项,模拟用top-kaux个失活latent进行重建的损失。
如此一来,即使是1600万latent的大规模自编码器,失活率也只有7%。
最后,论文一作表示稀疏自编码器的问题仍然远未解决,这项研究中的SAE只捕获了GPT-4行为的一小部分,即使看起来单义的latent也可能难以精确解释。而且,从表现优异的SAE到更好地理解模型的行为,还需要大量的工作。
Transformer NLP到底有没有智能?
智能的定义
和人脑的区别和差异
“性能差异”
- 场景:通过对一段句子进行划分、分句、解析起表达的意思
- 我的祖国是中国: 我/的/祖国/是/中国 => 我的/祖国/是/中国 => 我的祖国/是中国 => 我的祖国是中国
- 机器缺乏丰富的抽象、合理的分层、组合 => 抽象表达的效率比较低,通过暴力的记住所有的可能
训练
- 需要大量的数据来梯度下降,而不是用逻辑的方式来进行总结归纳
- 更大的模型,确实在抽象的时候更灵活了,更合理了,避免了固定卷积核的约束
用推理的临时态实现意识--CoT
背景和方法
众所周知,o1在推理阶段采用了一种思维链(Chain of Thought)的方法,将推理过程分解为多个离散的步骤。o1能够规划其推理步骤,评估中间结果,并在步骤出错或陷入僵局时进行回溯。
- 基础模型的训练(预训练和后训练)遇到瓶颈了
- 通过推理阶段的不断自我逻辑判断和思考实现更强的推理能力
- 自洽,在这个过程中前后的因果关系是自洽的
- 可以实现,更多深层次的思考
- 动态性,可以在思考的过程中不断的调整思考方向
- 把训练迁移到推理(运行态)
- 在推理的过程中实现“意识”,“意识”是AGI的关键能力
- 在self attention的基础上继续扩展了一个“动态性”的维度
- 在推理过程中不断寻找思路,实践,判断效果,实现了自动化的“蒙特卡洛树算法”
需要实现的前提
- 能自动的在推理的过程中压缩KV cache
- 能暂停输出,接受外界的输入,拼接到当前的kv cache中
- 能对当前的结论和临时状态进行判断和总结
- 怎么训练(改变模型的权重)?
- 好像只能通过不断的调整提示词来找到输出合理结果的方法
- 可以通过推理过程中,插入特定的外界输入来改变中间结果(kv cache)的方式来调整/训练
测试时训练(TTT)技术
能显著提高LLM进行逻辑推理和解决问题的能力。让大语言模型在推理时「边思考边执行」,即测试时计算(test-time compute)。这种方式能带来巨大的回报
传统的LLM主要依靠的是检索存储模式,但o3处理问题时,却是靠实时创建新程序,来解决不熟悉的挑战。
在不提高算法效率的前提下,暴力增加算力消耗,边际效应会原来明显,需要的算力将是指数级别的增加
思考的界面是是人类的语言
- 是不是有个更适合机器思考的语言?
- 人类不能用自然语言思考任何东西,比如数学和代码
- Chris Hay:这种语言的设计更适合 LLM,因此会减少为满足人类需求而设置的语法糖。所以编程语言本身将会发生演变。